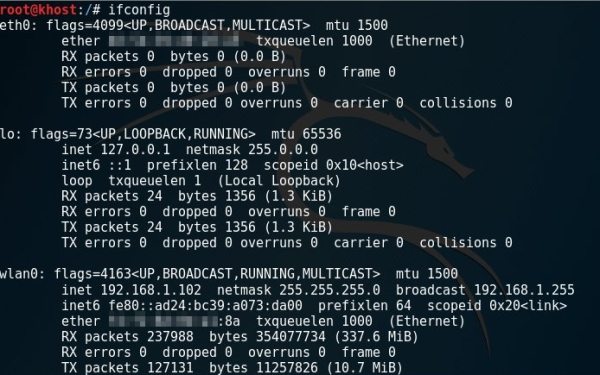
Dal punto di vista tecnico, una VPN, acronimo di Virtual Private Network, consente di creare una connessione protetta in un’altra rete via Internet. Questo offre un duplice vantaggio: da un lato tutto il traffico passa attraverso un tunnel crittografico che ne impedisce la leggibilità; dall’altro l’ip che i siti web vedranno sarà quello del server VPN a cui ci colleghiamo.
In questo post non scenderò in dettagli che risulterebbero eccessivamente ostici, ma mi limiterò a dare qualche dritta su come scegliere un buon servizio VPN. Non tutti i provider, infatti, forniscono lo stesso livello di anonimato e sicurezza, dunque affidarci al primo che capita potrebbe peggiorare la situazione esponendoci a rischi concreti per la nostra privacy.
Tengo a precisare che quando parlo di VPN mi riferisco solo a quelle a pagamento (del costo di circa 10 euro al mese, euro più euro meno). In Rete si trovano numerose VPN gratuite, ma le sconsiglierei per un semplice motivo: mantenere un’infrastruttura di server sparsi per il mondo comporta dei costi, e chi ti promette un accesso “free”, il più delle volte è interessato solo ai tuoi dati.
Ad ogni modo, qui di seguito elenco alcuni criteri utili per orientarsi tra le centinaia di fornitori VPN presenti sul mercato:
1) Nome della società e sede legale. Esempio: una società con sede negli Stati Uniti opera sotto la giurisdizione americana, dove la tutela dei dati personali viene sempre più spesso ignorata. Se l’obiettivo è proteggere la propria privacy, fornitori situati in paesi con leggi favorevoli in tal senso (come Panama, Hong Kong, Isole Vergini Britanniche, Seychelles, Taiwan ecc), possono rivelarsi una scelta azzeccata.
2) Logging policies. Nel gergo informatico i cosiddetti “log” sono file di testo che memorizzano informazioni quali indirizzo ip, data e ora di un evento, e-mail e credenziali di accesso. Quando si sceglie una VPN, è di fondamentale importanza che il provider specifichi nella Privacy Policy (il cui contenuto ha valore legale) se e cosa conserva di noi.
3) Metodi di pagamento. Com’è facile intuire, anche quando paghiamo stiamo lasciando tracce della nostra identità. Proprio per questo, alcuni provider hanno deciso di offrire maggiore anonimato ai propri clienti accettando Bitcoin e altre criptovalute.
4) Protocolli supportati. Senza scendere troppo nei particolari, esistono diverse tecniche di cifratura che consentono di creare una sorta di tunnel protetto per lo scambio di dati. Nel caso delle VPN, si chiamano PPTP, L2TP/IPsec e OpenVPN. Quest’ultimo è attualmente il protocollo più sicuro e utilizzato, quindi è da preferire agli altri due, soprattutto a PPTP, sviluppato da Microsoft diversi anni fa e ormai obsoleto.
5) Sistemi “Kill Switch”. Si tratta di una funzionalità avanzata offerta dai migliori provider, che salvaguarda gli utenti da eventuali leak dell’ip arrestando i programmi preventivamente specificati qualora la connessione alla VPN dovesse interrompersi o non riuscire per qualche motivo.
Beh, che dire? La scelta di buon servizio VPN è sicuramente un compito arduo, ma credo di aver toccato gli aspetti fondamentali della questione. Tuttavia, non bisogna dimenticare che i provider si basano sulla fiducia che riponiamo in loro, e se questa fiducia viene tradita, purtroppo non possiamo farci niente.