Breve PoC che mostra come crittografare rapidamente un file utilizzando il sistema a cifratura simmetrica fornito da GNU Privacy Guard o GPG. Questo metodo sfrutta la stessa chiave privata sia in fase di encryption che in fase di decryption, e risulta particolarmente comodo se si desidera cifrare solo alcuni dati e non si vuole impostare una coppia di chiavi (necessaria per la crittografia asimmetrica e le firme digitali).
GPG supporta diversi algoritmi di cifratura (ciphers), tra cui AES-256, Blowfish e CAST-5. È possibile vedere la lista completa digitando da terminale:
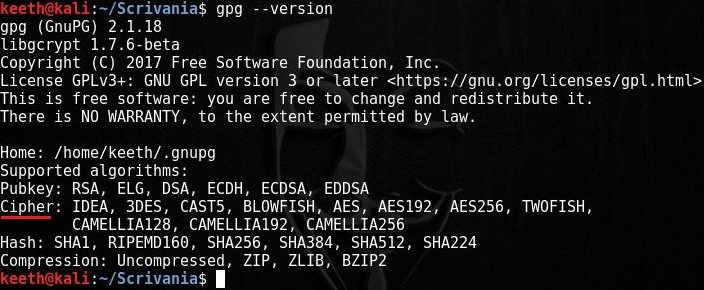
Di default, l’algoritmo utilizzato come cifrario simmetrico è AES-128, allo stato attuale praticamente incrackabile poiché, anche con un supercomputer, occorrerebbe un tempo pari a 1,02×10^18 anni, ossia 1 miliardo di miliardi di anni.
Per la sua affidabilità e robustezza, AES è stato scelto dal governo degli Stati Uniti come standard per proteggere informazioni classificate fino al livello top secret, che è il livello massimo di segretezza e richiede chiavi a 192 o 256 bit (rispettivamente AES-192 e AES-256).
Tornando a GPG, ipotizziamo di voler criptare un semplice file di testo. L’opzione –cipher-algo ci permette di scegliere un algoritmo di cifratura tra quelli disponibili. Prima che il documento venga crittografato, sarà richiesta una passphrase da cui derivare la chiave privata per il processo di encryption/decryption. Va da sé che più la passphrase è forte e più il rischio che qualcuno possa indovinarla si riduce:

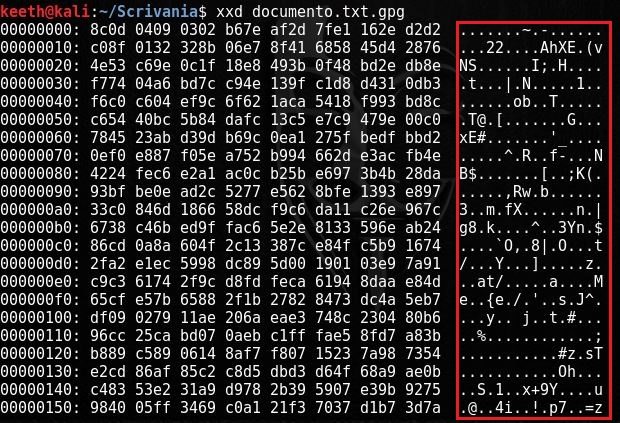
A questo punto, se diamo un’occhiata ai file, vedremo un binario con estensione .gpg, che contiene il nostro testo cifrato usando AES-256:

Possiamo aprirlo con un editor esadecimale per constatarne l’effettiva illeggibilità:
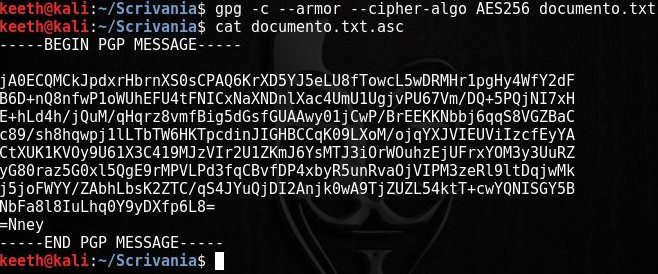
Nel caso in cui sia necessario incollare il contenuto criptato nel body di una mail (supponendo che le parti abbiano condiviso la chiave di persona o tramite un canale sicuro), è opportuno convertire il binario in un formato “user-friendly”, ossia in una sequenza di caratteri stampabili e perfettamente leggibili. A tal proposito, ci viene in aiuto il parametro –armor, che genera un file .asc con un testo codificato in base64:
È importante sottolineare che entrambi i file (.gpg e .asc) hanno lo stesso livello di cifratura (AES-256), solo che il primo è in formato binario, mentre il secondo è in formato ASCII.
Per decriptare il documento si usa il comando –decrypt nella seguente sintassi:

Con l’opzione –output è possibile specificare un file all’interno del quale scrivere il contenuto in chiaro.
NB: al momento del processo di decrittazione verrà richiesto di inserire nuovamente la passphrase. Qualora sia stata smarrita o dimenticata, sarà del tutto impossibile sbloccare la chiave, e dunque accedere al contenuto del file.